국립국어원, 11일 국립중앙박물관 대강당에서 개최
<사진 1>
1998년부터 2007년까지 10년, 연 200여 명의 연구진 참여
1998년 시작된 21세기 세종계획 사업은 2007년까지 세계적 수준의 말뭉치 구축과 컴퓨터가 인식할 수 있는 전자사전 개발에 100억 예산을 투여했으며, 한민족 언어 정보화, 우리말 정보화와 세계화를 위한 각종 프로그램 개발, 우리말 표준화를 위한 전문용어 정비, 문자코드 표준화 사업을 병행하여 수행하였다.
소설책 4천 건 분량의 세계적 수준의 말뭉치 구축
급속하게 변화하는 21세기 정보화 사회에서 국민 전체의 언어·문화 생활을 향상시키고 과학 기술 및 학문을 발전시키기 위해서는 대규모 언어 자료를 축적하여 정보·지식으로 가공하는 일이 무엇보다도 중요하다. 말뭉치 구축 사업은 이러한 필요를 바탕으로 신문, 잡지, 소설 등 다양한 자료를 컴퓨터에 입력하였으며 필요한 자료를 검색할 수 있도록 프로그램을 개발하였다.
서구 선진국의 경우 국가와 수많은 정보 산업 관련 기업체, 기술 개발자를 중심으로 대규모 말뭉치 구축 사업이 진행되었다. 영국 국가 말뭉치(British National Corpus)는 1991년부터 1994년까지 1억 어절의 말뭉치를 구축하였고, 중국은 2000년부터 중·영, 중·일 병렬 말뭉치를 베이징대학교와 베이징외국어대학교를 중심으로 구축하였다. 일본 역시 1986년부터 1994년까지 단어 위주의 EDR Corpus를 구축하였고, 일본의 국립국어연구소가 2006년부터 2011년까지 1,000만 단어를 목표로 일본어 균형 말뭉치(Japanese balanced written corpus)를 구축하는 일을 시작하였다. 세종계획 말뭉치는 2억 어절(소설책 4,000권 분량)의 규모로 세계 어느 나라보다 규모가 크며, 한마루와 같은 검색 프로그램을 개발하여 단어 검색이 가능하도록 하였다.
다음 사진은 구축된 말뭉치를 대상으로 ‘가방’을 검색한 결과이다.
자연어 기계처리를 위한 전자사전 개발, 한국어 60만 어휘 규모
21세기 세종계획의 또 한 축은 기계가 인식할 수 있는 전자사전의 개발이다. 언어 정보의 자동 처리를 위한 전자사전은 연구자들의 필요에 따라 부분적으로 만들어졌으나, 21세기 세종계획의 전자사전은 60만 어휘에 달하는 대규모의 범용적 전자 사전으로, 특정한 유형이나 영역의 기계 처리 작업에 국한되지 않고, 정보 검색, 텍스트의 분석과 산출, 자동번역, 다국어 사전 구축, 인쇄 사전 구축 또는 한국어 교육이나 순수 연구 등에 두루 활용될 수 있으며, 더 나아가서는 향후의 진보된 인공지능 개발 환경에도 유연하게 적용될 수 있도록 개발되었다.
남북한 언어 비교, 남북한 방언, 어휘 역사 검색 가능
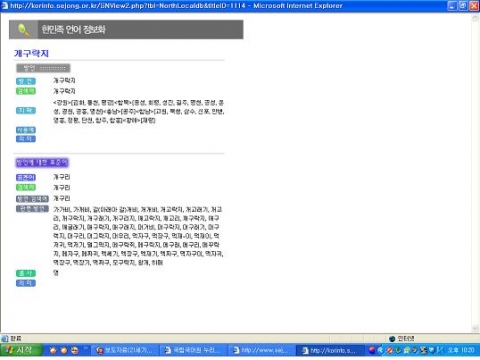
한민족 언어 정보화 사업은 한민족의 언어 정보를 쉽게 검색할 수 있는 시스템을 만들기 위해 언어 규범 자료, 남북한 언어 비교 자료, 방언 자료, 어휘 역사 자료를 순차적으로 구축하고 이를 검색할 수 있는 시스템을 개발한 사업이다. 예를 들어 <사진 1>처럼 지역 방언 ‘개구락지’를 입력하면 해당 표준어가 무엇인지 알 수 있고 이 방언을 사용하는 지역과 관련된 다른 지역의 방언에 어떤 것들이 있는지 확인할 수 있다.
문자코드 표준화, 전문용어 정비, 글꼴 지원
21세기 세종계획 사업은 국제적인 문자코드의 표준화와 전문용어 정비에도 노력을 기울였다. 고려대학교 민족문화연구원에 문자코드연구센터를 두어 현대 컴퓨터에서 입력할 수 없는 한자, 옛 글자 등을 수집하고 이 중에 한자 404자를 국제표준문자에 등록하였다. 전문용어 정비 사업을 통해서 14개 분야, 17만 단어의 한영 대응 목록을 만들었다. 이 사업을 통해 전문용어 정비의 필요성을 학계에 각인시켰으며 전문용어 정비를 위해 국어학적 검토의 중요성을 학계에 재확인시켰다.
국어정보화 사업의 일환으로 추진된 21세기 세종계획 사업은 급격하게 변화하는 정보화 시대에 걸맞게 새로운 비전을 가지고 그동안 축적한 결과물을 산업적으로 활용할 수 있는 2단계 사업을 계획 중이다.
이날 행사에는 음성합성 및 음성인식 엔진 업체 코아보이스, 자동번역업체 엘엔아이소프트, 한국어 맞춤법/문법 검사기 개발 업체 나라인포테크의 시스템 시연이 있으며, 과학기술 지식 정보 관리시스템과 온톨로지 기반의 정보 관리 시스템을 개발한 한국과학기술정보연구원의 기술 설명과 시연이 있다. 또한 글꼴디자인 업체인 윤디자인 연구소와 산돌커뮤니케이션의 글꼴 전시도 마련되어 있다.
국립국어원에서는 이날 21세기 세종계획 성과물 시디와 발표 자료집, 기념품 등을 참석자들에게 나누어 줄 예정이다.
국립국어원 개요
국립국어원은 우리나라의 올바른 어문 정책을 연구·수행하고자 설립된 문화체육관광부 소속 기관이다. 역사적으로는 세종대왕의 한글 창제를 도운 ‘집현전’의 전통을 잇고자 1984년에 설립한 ‘국어연구소’가 1991년 ‘국립국어연구원’으로 승격되고, 2004년에 어문 정책 종합 기관인 ‘국립국어원’으로 거듭났다.
웹사이트: http://www.korean.go.kr
연락처
문화관광부 국립국어원 양명희 국어정보화팀장 02-2669-9722

